Hey folks. First time, long time (a joke that makes sense only to a few olds, probably).
I’m interested in a proper archiving workflow for Scalar projects, by which I just mean running webrecorder on books/sites (because simple HTML flattening doesn’t work) and hosting those .wacz files in a player somewhere on the Internet, probably our DOOO. I have the Site Archiving Toolkit installed running in Reclaim.cloud (thank you @taylorjadin) and have been happily using it on a number of things, but Scalar still gives me fits.
[As a new user I can only include two links in a post, so I’ll paste the links I’ve embedded in the following paragraph in replies to the thread.] This does not appear to be a fault of the Toolkit: the [Stanford infrastructure] linked in [this post from a couple years ago] is also having challenges (viz. [Black Quotidian] and [When Melodies Gather] as they should render in the webrecorder player). Further, neither the .wacz files for my crawls nor those created/hosted by the Stanford folks will render in [the replayweb.page interface].
Is anyone wrestling with this, too? Or have an alternative workflow that has worked? (Or observations about where I’m going wrong?)
(viz. Black Quotidian and When Melodies Gather as they should render in the webrecorder player). Further, neither the .wacz files for my crawls nor those created/hosted by the Stanford folks will render in the replayweb.page interface.
And if that works well for you you can click on the " webrecorder-teaching.jacobheil.com-2024-04-01T192802.zip" link to download a zipped copy of that. That zipped copy can then be uploaded to just about any web server including on DoOO.
Hopefully that helps but let me know if you have any other questions here or if I’m misunderstanding your question!
Just one more piece of info. When I download the WACZ file, and upload on https://replayweb.page/ I get the same result on Google Chrome.
I was curious, because I wondered if it was Taylor’s implementation where he downloaded the JS files from the CDN, and then embedded those into the folder. Happy to report that my suspicion was misplaced, and I’m seeing the same error on official WebRecorder pages, which makes me think its a bug that should be reported.
Thanks for clicking through here, @taylorjadin and @Ed_Beck! And thanks, Ed, for providing the full report on browsers. I just popped back over here to ask Taylor what browser he was using, but you confirmed my suspicion that something is indeed up with browsers. (I had run the same tests you had at replayweb.page as well, so I’m grateful to have these confirmed.)
I found this bit of documentation about CORS settings and I wonder there is something in there to help? i.e. it’s not Taylor’s implementation but maybe the setting need to be tweaked because somewhere along the line to allow for all header types? (Or something… I’m mostly out of my depth here.)
I’ll report that bug, though. Thanks for that note.
Yes, I was using Firefox, but testing in Chrome is leading to the same problem for me too.
The fact that it also doesn’t work when uploading the file to replayweb.page makes me think this is related to a bug in their “replay” code. My toolkit is going to download the latest version of that javascript every time you do a crawl, which is likely the same/similar to whats on replayweb.page. I wonder if an older version will also be broken here or not. I might play around with that a bit.
This is very strange as it seems to be specific to this crawl and Chrome and I would agree with Ed, worth reporting.
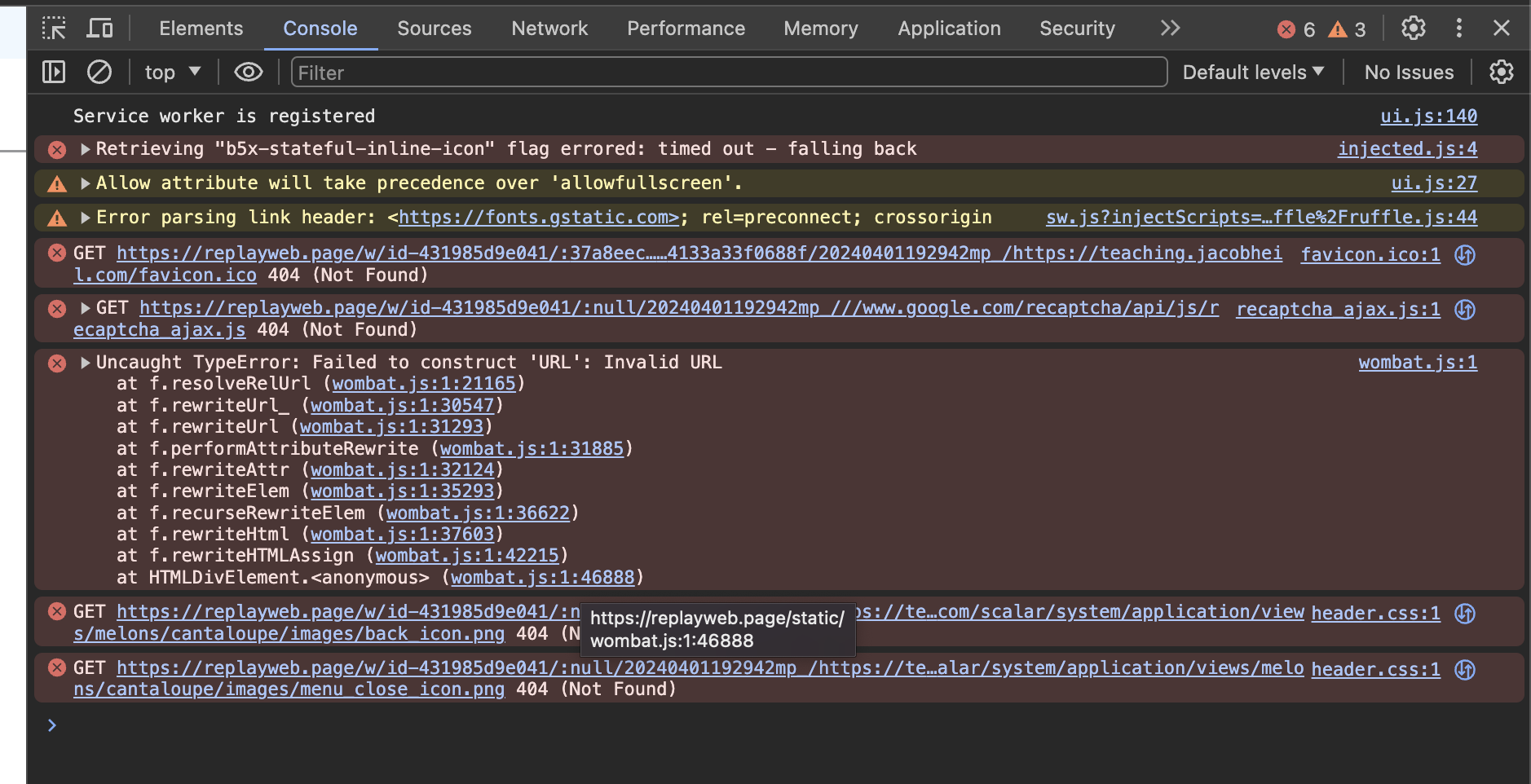
I think this error from wombat.js in the browser console is the relevant one:
Failed to load resource: the server responded with a status of 404 (Not Found)
wombat.js:1 Uncaught TypeError: Failed to construct 'URL': Invalid URL
at f.resolveRelUrl (wombat.js:1:21165)
at f.rewriteUrl_ (wombat.js:1:30547)
at f.rewriteUrl (wombat.js:1:31293)
at f.performAttributeRewrite (wombat.js:1:31885)
at f.rewriteAttr (wombat.js:1:32124)
at f.rewriteElem (wombat.js:1:35293)
at f.recurseRewriteElem (wombat.js:1:36622)
at f.rewriteHtml (wombat.js:1:37603)
at f.rewriteHTMLAssign (wombat.js:1:42215)
at HTMLDivElement.<anonymous> (wombat.js:1:46888)
/w/id-431985d9e041/:null/20240401192942mp_/https://teaching.jacobheil.com/scalar/system/application/views/melons/cantaloupe/images/back_icon.png:1
Awesome! I’ll make some time later in the week to dig through and see what exactly would need to be updated on your side, it might just mean we need to download the newest version of their replay javascript.
Ok so I just looked at this, and it looks like it is already fixed, no further action needed on our end! I was thinking that we were going to need to update the copy of the javascript that got loaded with the archive, but that doesn’t seem to be the case!