We’ve been running a Reclaim Hosted discourse site for our UDG Agora project, but it looks like they will not be using it in the future. I’m being asked if there is any way to archive it.
I read a few threads mentioning using httrack… but that’s likely what the Mac app Site Sucker uses under the hood. Curious if anyone has given it a try, or thoughts on how to convert discourse to a static archive.
I’d be curious if Sitesucker works since Discourse does all that fancy lazy-loading by JavaScript. Although maybe there are settings to handle some of that I haven’t played with.
It’s messy- I did a full site suck and so far, it sucks. I tried the “Web Views” options in Site Sucker because it sounded it would deal with lazy loading.
So far I am having to disable some of the discourse ember.js, had to redo the font-awesome, am using CSS to hide buttons and things not needed in archive… and still not quite there. I think I can get out one to a reasonable record, but it’s a messy route.
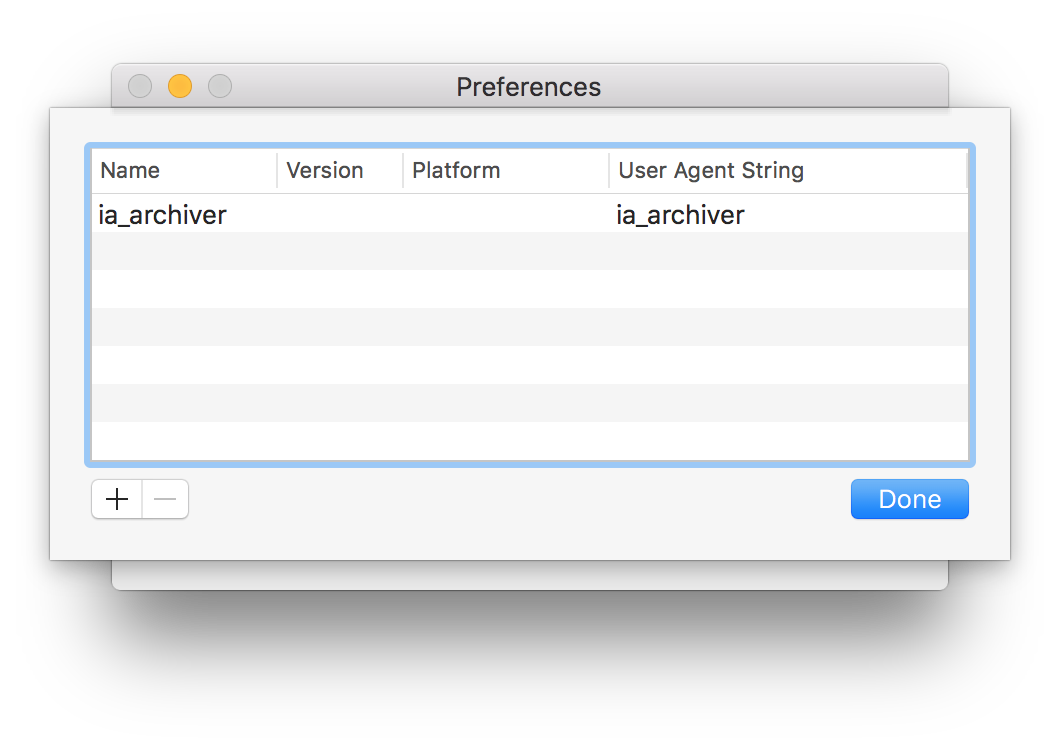
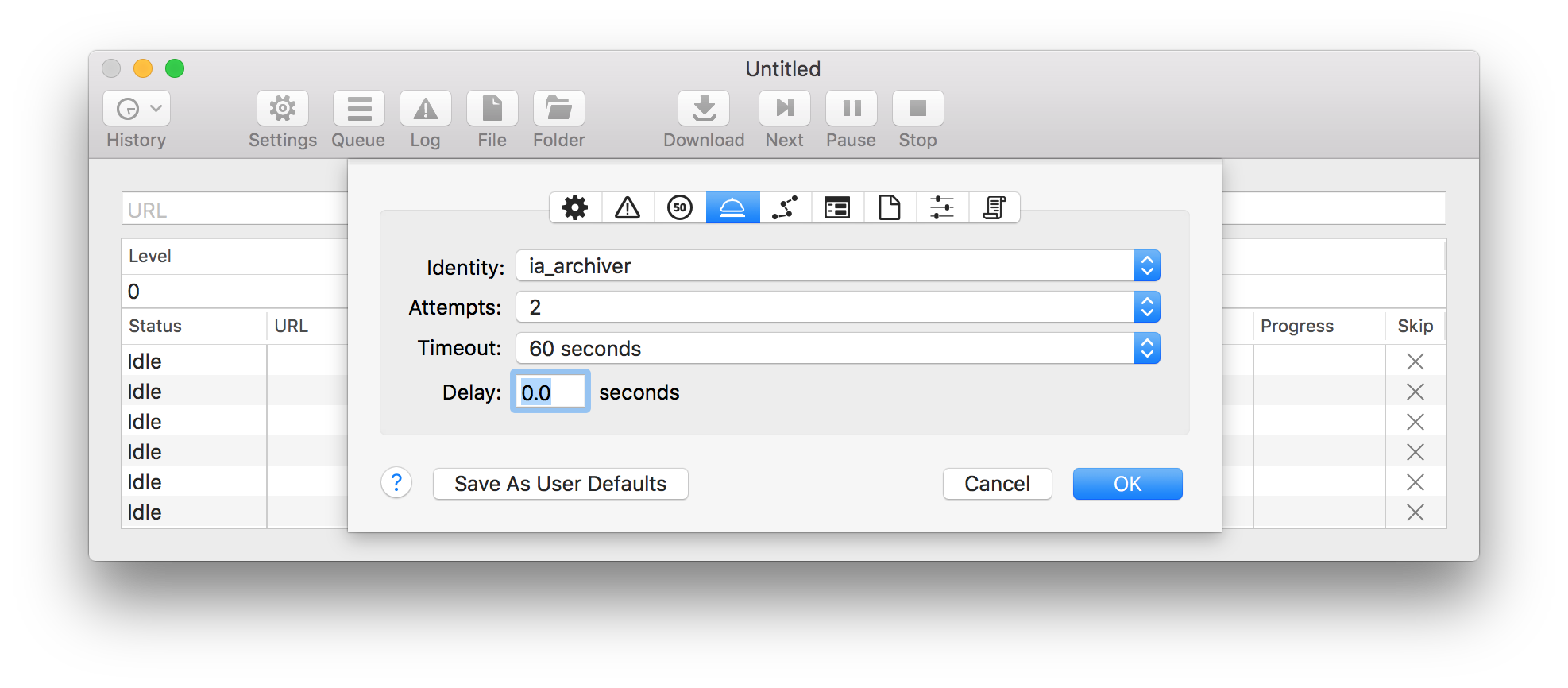
This method worked for me with the ia_archiver user agent @cogdog . I got the HTML version of all pages using Site Sucker. Might not be visually representative of what the forum looks like but all the content is there which I think is the important piece here.
Maybe I did not spend long enough seeing what that tool did.
Here’s the need. My client has a discourse site. They no longer plan to use
it as a discourse powered site (and maybe dont want to pay to keep it
going). But they want an archive of the conversations. So how can I create
a site that has the content as HTML and not rely on discourse any more, an
archive.
What i thought I saw in the tool you sent was something that recorded an
experience moving throughj the site, which might mean following every
discourse thread. ??
No, I shouldn’t have suggested anything without knowing what the problem. You have always been so helpful to me, I just jumped the gun trying to help. Not to worry. You’re right, the tool I suggested would be unwieldly.
The ‘-https://yoursite.edu/users* -*.rss’ bit prevents httrack from downloading files matching those patterns. You might choose to include those patterns or exclude others.
The ‘-x -o’ combo replaces both external links and errors with a local file indicating the error. So, for example, we don’t link to user profiles on the original that weren’t downloaded locally.
The ‘-M10000000’ restricts the total amount downloaded to 10MB. There appears to be some post processing and downloading of supplemental files that makes the total larger than this anyway.
The ‘–user-agent “Googlebot”’ should not be necessary if the forum is powered by a recent version of Discourse.
That will probably take several minutes to run. If it works and you’re happy with the results, try running it overnight with a larger -M value.
If that doesn’t work to your liking, you might try the Discourse Archival Tool that I wrote. It’s really tailored for my specific needs, though. On the other hand, if you’re comfortable with Python, HTML, and CSS, it should be pretty easy to hack it to your purposes.
Both have advantages and disadvantages and there’s really not a perfect solution. I do hope that helps some, though!
Totally appreciate this Mark, will be trying soon. I just hope to get a basic archive, and our discourse was not super active, but there is stuff worth saving. I speculate under the hood the Site Sucker Mac OSX app is calling HTTrack.
No, I don’t think that’s correct. HTTrack is GPL so, if SiteSucker was using it, it too would have to be GPL but it’s not.
Also on the server side, you can see that they have different user agent strings. Which, makes me realize - if you know and like SiteSucker, you should be able to use it, if you set the user agent identity correctly. I’d recommend setting to to Googlebot simply because that works for HTTrack. I don’t have SiteSucker so I can’t tell you how to do this, but it looks like you can do it, according to the documentation. Just scroll to the bottom where it you see the heading Identity.
You know, I think this is exactly what @timmmmyboysuggested before, though I guess he recommended ia_archiver.