I’ve got a fleet of old Wordpress sites I want to keep but have no need to keep running as Wordpress- they require updates, they attract spam-- all I want is to keep the links alive.
I just tested out the WP Static HTML Output plugin and it does a good chunk of the work, except it does not handle relative links well, so it took a few sweeps of global search and replace to local-fy all links and file references. I also had to remove the search form, and if any comment forms are still hanging around, they wont do anything.
Here is the site, with Wordpress completely dismantled http://secretrevolution.us/ It was a pretty small site.
Just curious if anyone has tried other approaches. If there was something automatic, scripted, it would make a good tool to have in the Reclaim Tool box.
I like what you are doing here, and I have a bunch of sites that are old and need to be retired as straight-up HtML sites. I know Tim and Martha were discussing doing something like this for UMW Blogs at some point last year in order to preserve that archive, but also liberate the system from history. I also know Tim is a big fan of Site Sucker (http://ricks-apps.com/ -I believe this is the right app) for OS X that downloads sites on the web to HTML. I have not tried it yet, but I want to. And hearing about the clean-up you’re doing around the web hosting garage is inspiring for wanna-be organizers like me.
I love SiteSucker, though I do wish there was something that could work more programmatically on the web (it being a desktop app has its limitations there). It does handle scripts and relative URLS very very well. Some example URLS:
That used to be a multisite and I got tired of maintaining themes and plugins for really old sites that would no longer be receiving updates so this was a nice compromise. It wouldn’t work with search and contact forms but that’s to be expected I think. I do think it even crawls tag/cat pages as well. I’m a big fan.
This is great! I’m beginning to think I’m psychic (or psycho). I no sooner start thinking about "oh, I’m gonna need a way to do xxxxx (like convert older WP sites into static HTML) and, lo, @cogdog@jimgroom and @timmmmyboy and the rest of the Reclaim community solve it for me. Thnks.
Tim is always ahead of the game. That Wordpress plugin choked on a bigger site, so I broke out my copy of Sitesucker. This Wordpress site, used from 2005-2011 is now all static html
I wrote up some notes- the biggest things are do do some pre-work to the site to remove forms that wont work (remove search forms, turn off all comments). I would also recommend reading more in the site sucker settings, I should have kept mine limited to a directory and it started walking my whole domain outside the WP install.
It does a fantastic job- all full URL link are made relative, so it could also be hung at a new domain.
I’m pretty sure Sitesucker is just a fancy GUI wrapper for wget. On Linux if you’re comfortable in Terminal I would try wget following the guide at Make Offline Mirror of a Site using `wget` – Guy Rutenberg and see if that works. There are lots of nifty flags with that command to control how it archives a site.
Ok so wget is actually really good and opens up some interesting possibilities here. I tried the command from that linked guide
wget -mkEpnp https://blog.timowens.io
when logged in via ssh to my Reclaim Hosting account and it generated a folder named blog.timowens.io with everything inside it. It took 5 minutes and 43 seconds to download 55Mb of stuff and convert the links in all of the pages to local relative ones. I uploaded it to Amazon S3 which can do static file hosting so that folks could see the result.
I could see combining wget with s3cmd and automating this whole thing which would be really interesting. If nothing else it would also just be crazy cool to be able to have a cPanel app that could take a URL as input and throw a folder in your hosting account with a static archive.
Making this even more interesting, I tested the wget functionality with a local hosts file and was able to archive a site on a server for which the domain expired almost a year ago. Damn that’s cool.
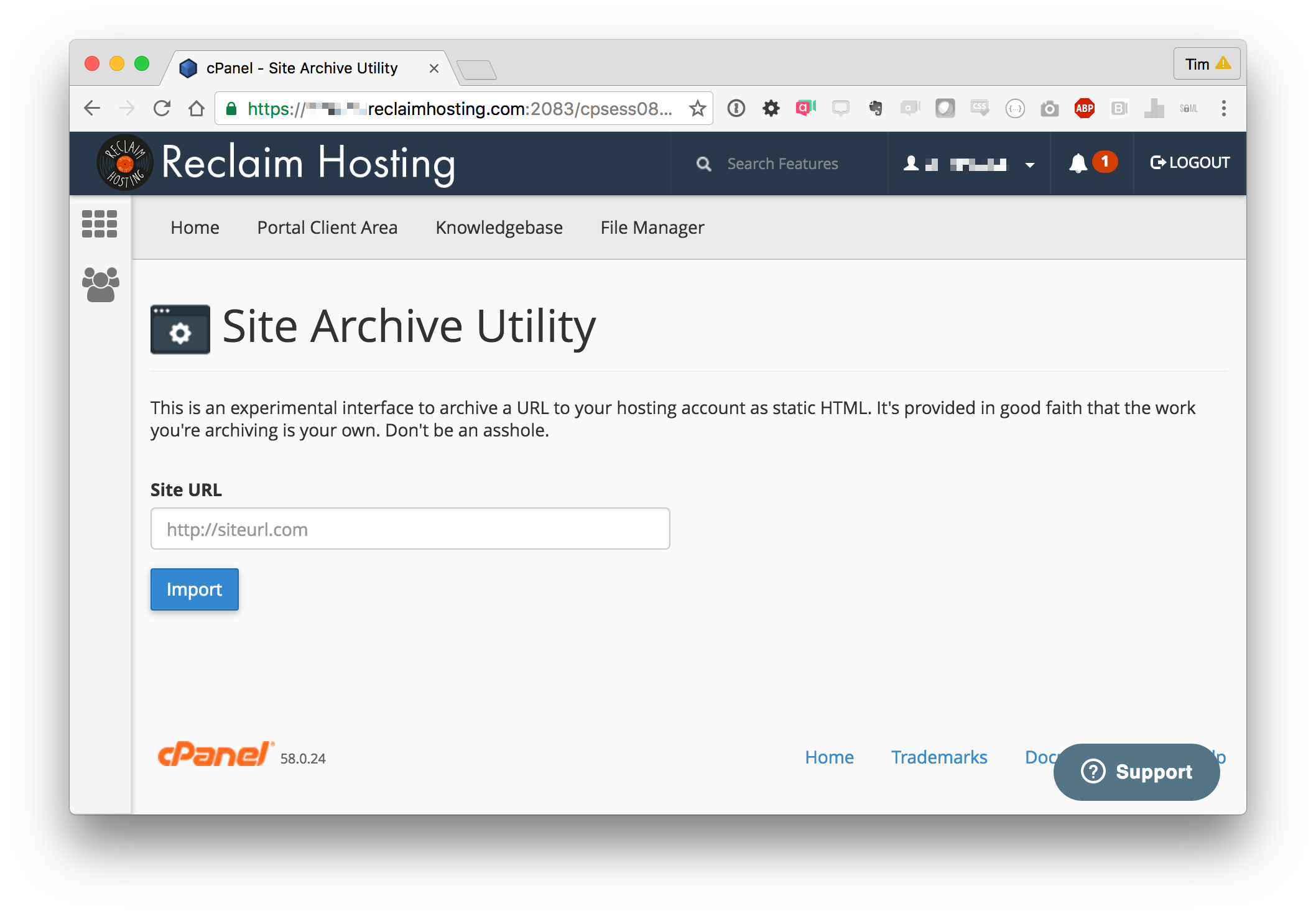
I’ve started building the plugin this could become, just a dummy interface for now. I’ll probably start with a basic “Give me a URL and the folder location you want to save to” and then once that’s working we can look at fancier options like scheduled archive, S3 and other remote archives, etc.
If you want to make sure people are archiving only their hosted sites, I wonder if you could do something like the way Google does site verification - generate a file with some kind of hashed name/code in it that has to be loaded at the root level of the server. The script could then do some kind of verification to make sure the person is only archiving a site they manage
Hey all. If you take a database backed site like Wordpress or Drupal and archive it to “flat” HTML, you take a one way trip to losing all metadata.
What I mean by that is, information about posts and pages like date created, author, tags, categories, etc.
Especially for large archives, it means you can’t easily remix the site content again.
I’ve been using Jekyll, a static site generator, for this same purpose. Exporting to Jekyll means individual posts or pages are exported into HTML / markdown, with YAML front matter that contains this metadata.
That last bit was a bit gibberish if you haven’t played with Jekyll yet. There is a block of text at the top of each text file that has author, tags, etc.
The downside to exporting to Jekyll is that it doesn’t preserve the theme (because it’s saving the content, not the presentation layer). And, that it’s learning a little bit of Jekyll.
Appreciate the clarification and that’s a fair point, switching to a different CMS like Jekyll is definitely more flexible if you want to be able to reuse the content again in another context versus simply archiving it. (I also like @cogdog’s idea of simply keeping a dormant copy of the database or SQL backup in case you want to revert). But if the goal is to actually archive I’m not sure I agree the metadata is lost. Look at Investing in Community as an example. Viewing the source and looking at the post itself all the tags and other information are completely intact. You’re right that I can’t turn this into anything else, but as an archival method it still seems to me like a really nice option. I suppose with any archiving methodology though the rule of thumb is to have a variety of formats to support longevity.
yep, wget has been my go to UNIX utility for years. You can run it on Mac, Win, Linux pretty much anything. I use it to crawl websites and create a local mirror of them getting all related files. Since web apps hide the server side code and just deliver the HTML to the browser, that’s all wget sees so you end up with a local html archive.